强化学习算法开发工具OpenAI-Gym的使用
一、OpenAI与Gym
- OpenAI,由诸多硅谷、西雅图科技大亨联合建立的人工智能非营利组织。
2015年埃隆·马斯克与其他硅谷、西雅图科技大亨进行连续对话后,决定共同创建OpenAI,希望能够预防人工智能的灾难性影响,推动人工智能发挥积极作用。 - gym 是 OpenAI 针对强化学习推出的诸多环境的集合,我们可以直接在这些环境上使⽤各种强化学习算法来训练我们模型,这样我们就可以专注于强化学习算法本⾝⽽不是编写环境了。
简单来说,Gym为我们提供了测试环境,我们需要做的就只有编写强化学习算法,来验证我们的算法。
OpenAI网站为:openai/gym: A toolkit for developing and comparing reinforcement learning algorithms. (github.com)
二、Gym的测试环境
Gym包含了特别多的测试环境,主要包括以下几类:
- Classic control 和 toy text: 这部分内容大部分来自强化学习的论文,可以完成小规模任务。
- Algorithmic: 这部分内容用于执行计算,比如多位数相加、反转序列等等。
- Atari: 这部分内容可以用来玩雅达利游戏,Gym以一种易于安装的形式集成了 Arcade学习环境
- 2D and 3D robots: 这部分内容可以通过仿真控制机器人,这些任务使用MuJoCo物理引擎,MuJoCo专门用于快速精准的机器人仿真控制,
三、Gym编程框架
import gym
env = gym.make("CartPole-v1")
observation, info = env.reset(seed=42, return_info=True)
for _ in range(1000):
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
observation, info = env.reset(return_info=True)
env.close()
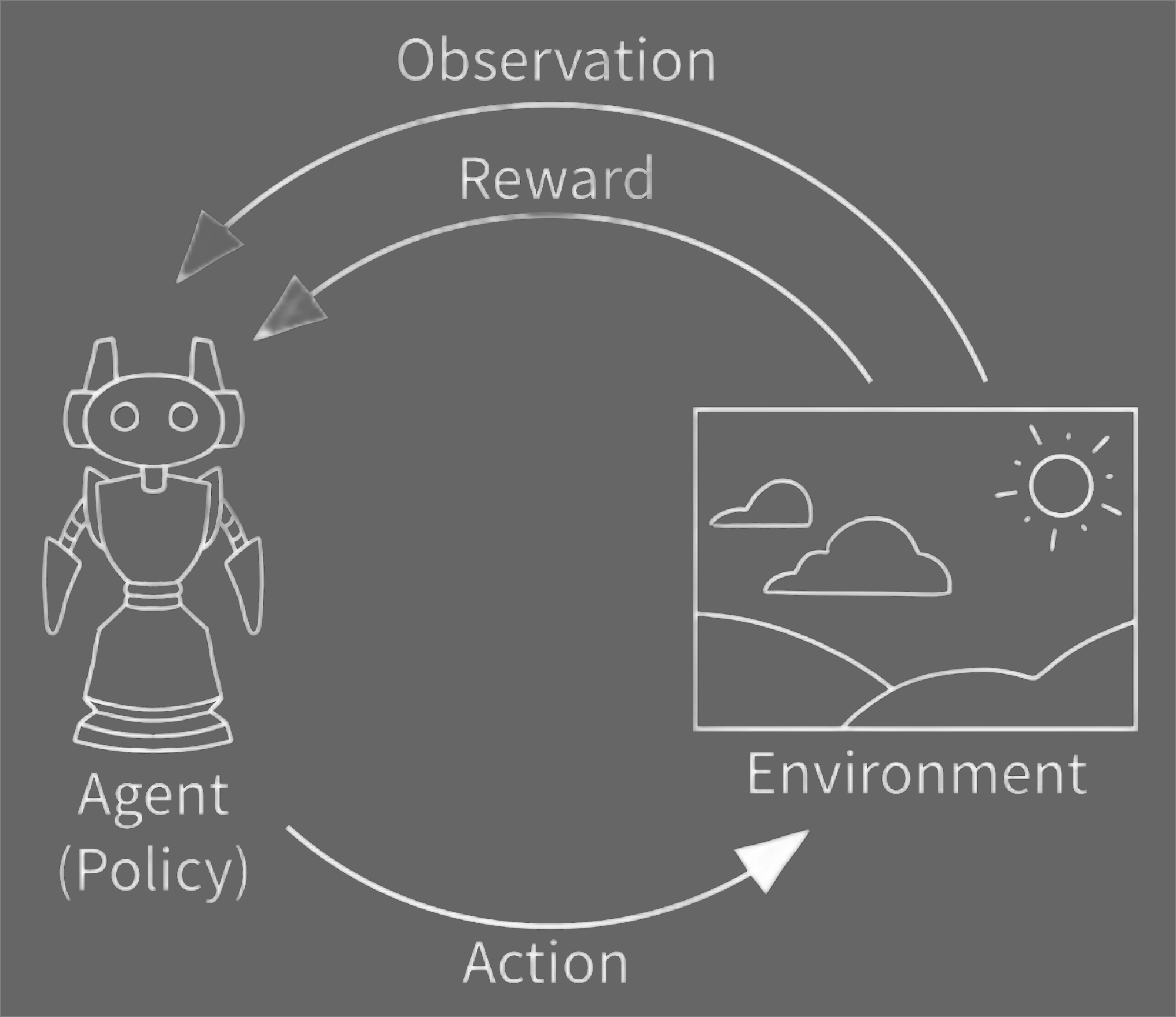
OpenAI Gym主要是训练Agent与Environment进行交互。
四、重要结构
1. Environments
与环境交互的方法:
reset: 将环境重置为其初始状态,并返回与初始状态对应的环境的观察结果。step: 此函数将操作作为输入并将其应用于环境,从而导致环境转换为新状态。 reset 函数返回四件事:
(1)observation(object):特定环境的观测值,比如相机的数据、角度、角速度等等;
(2)reward(float):根据上一个操作得出来的奖励值,改值大小总趋向于增加总奖励值的大小;
(3)done(boolean):无论是否到了重置环境的时候,大部分任务被分成完全定义的不同环节,如果 done 变为 True 了,那么表明该环节被停止了;
(4)info(dict):诊断信息对于调试很有用处。
2. Spaces
每一个环境都会有一个 action_space和一个 observation_space .
他们的属性都是 Space,它们描述了有效操作和observation的格式。
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
#> Discrete(2)
print(env.observation_space)
#> Box(4,)
离散(Discrete)空间的 action 为 一定范围内的非负整数,在这个例子中,合法的 action 是 0 或 1。Box空间是n维的,所以合法的 observations 是一个4维向量,我们可以查看 Box 的范围。
print(env.observation_space.high)
#> array([ 2.4, inf, 0.20943951,inf])
print(env.observation_space.low)
#> array([-2.4, -inf, -0.20943951, -inf])
Box 和 Discrete 是最常见的 Space。
我们可以对一个 Space 进行采样或者查看其中的元素:
from gym import spaces
space = spaces.Discrete(8) # Set with 8 elements {0, 1, 2, ..., 7}
x = space.sample()
assert space.contains(x)
assert space.n == 8
3. Wrappers
通过继承gym.Wrapper类来对环境进行自定义。
比如可以对action_space和 observation_space的数据结构进行修改。
对返回值obs, reward, done, info进行自定义等等。
Wrappers分为以下几种:ActionWrapperObservationWrapperRewardWrapperAutoResetWrapperGeneral Wrappers
一个典型的结构如下:
class DiscreteActions(gym.ActionWrapper):
def __init__(self, env, disc_to_cont):
super().__init__(env)
self.disc_to_cont = disc_to_cont
self._action_space = Discrete(len(disc_to_cont))
def action(self, act):
return self.disc_to_cont[act]
if __name__ == "__main__":
env = gym.make("LunarLanderContinuous-v2")
wrapped_env = DiscreteActions(env, [np.array([1,0]), np.array([-1,0]),
np.array([0,1]), np.array([0,-1])])
print(wrapped_env.action_space) #Discrete(4)
同时,我们还可以对这些Wrappers进行嵌套,
import random
class ObservationWrapper(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
def observation(self, obs):
# Normalise observation by 255
return obs / 255.0
class RewardWrapper(gym.RewardWrapper):
def __init__(self, env):
super().__init__(env)
def reward(self, reward):
# Clip reward between 0 to 1
return np.clip(reward, 0, 1)
class ActionWrapper(gym.ActionWrapper):
def __init__(self, env):
super().__init__(env)
def action(self, action):
if action == 3:
return random.choice([0,1,2])
else:
return action
env = gym.make("BreakoutNoFrameskip-v4")
wrapped_env = ObservationWrapper(RewardWrapper(ActionWrapper(env)))
4. Vectorized Environments
这部分功能主要是为了实现并行加速计算。
Gym 提供两种类型的矢量化环境:
gym.vector.SyncVectorEnv,其中按顺序执行环境的不同副本。gym.vector.AsyncVectorEnv,其中环境的不同副本使用多处理并行执行。这将为每个副本创建一个进程。
5. Playing within an environment
实现键盘控制
from gym.utils.play import play
play(gym.make('Pong-v0'))
使用按键映射实现自定义键盘控制
import gym
import pygame
from gym.utils.play import play
mapping = {(pygame.K_LEFT,): 0, (pygame.K_RIGHT,): 1}
play(gym.make("CartPole-v0"), keys_to_action=mapping)
使用返回函数实时绘制统计信息
def callback(obs_t, obs_tp1, action, rew, done, info):
return [rew,]
plotter = PlayPlot(callback, 30 * 5, ["reward"])
env = gym.make("Pong-v0")
play(env, callback=plotter.callback)

