强化学习与常用环境
一、强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习是机器学习领域之一(与监督学习、无监督学习并列,不存在包含关系。),受到行为心理学的启发,主要关注智能体如何在环境中采取不同的行动,以最大限度地提高累积奖励。
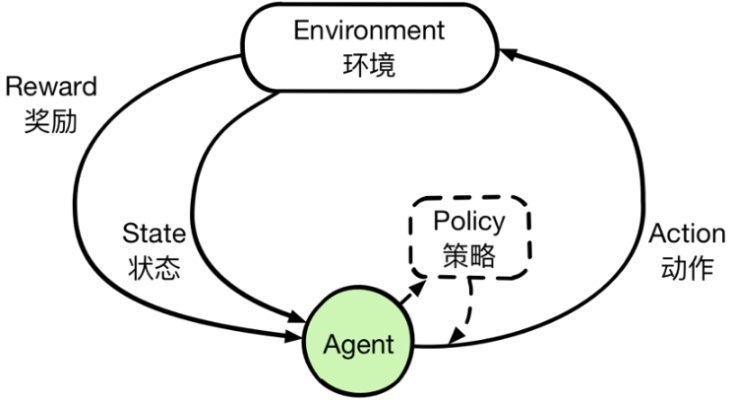
强化学习主要由智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)组成。智能体执行了某个动作后,环境将会转换到一个新的状态,对于该新的状态环境会给出奖励信号(正奖励或者负奖励)。随后,智能体根据新的状态和环境反馈的奖励,按照一定的策略执行新的动作。上述过程为智能体和环境通过状态、动作、奖励进行交互的方式。
强化学习应用主要包括AI游戏(如Atari),推荐系统,机器人控制(如Ng无人机飞行)。
智能体通过强化学习,可以知道自己在什么状态下,应该采取什么样的动作使得自身获得最大奖励。由于智能体与环境的交互方式与人类与环境的交互方式类似,可以认为强化学习是一套通用的学习框架,可用来解决通用人工智能的问题。因此强化学习也被称为通用人工智能的机器学习方法。
比如Alpha Go与AlphaGo Zero均是基于深度强化学习所言发的,在弱监督信息下通过”Trial and error”来自我学习。
二、机器学习、深度学习和强化学习的关系和区别

三、实验场景
近些年来,随着深度强化学习(DRL)变得越来越热门,各种深度强化学习研究平台也变得越来越多。
这些实验场景有:简单的toy场景、3D迷宫、第一人称射击游戏、即时策略类游戏和复杂机器人控制场景等。
| 名称 | 简介 | 研发机构 | 语言 | 平台 | 官方介绍 |
|---|---|---|---|---|---|
| MuJoCo | 用于机器人控制优化 | OpenAI | Python | ||
| OpenAI Gym | 研究强化学习算法的toolkit,实验场景包括:经典的Cart-Pole, Mountain-Car到Atar,Go,MuJoCo | OpenAI | 官方网站为https://gym.openai.com/,源码位于https://github.com/openai/gym | ||
| RLLib | 研究强化学习算法的框架,OpenAI Gym支持更广泛的环境 | 官方网站为https://github.com/openai/rllab | |||
| DeepMind Lab | 3D迷宫场景强化学习平台 | DeepMind | 官方介绍https://deepmind.com/blog/open-sourcing-deepmind-lab/。论文 https://arxiv.org/pdf/1612.03801.pdf。源码位于https://github.com/deepmind/lab。 | ||
| TORCS | 跨平台的赛车游戏模拟器 | 官方网站:http://torcs.sourceforge.net/ | |||
| PySC2(StarCraft II) | 即时策略游戏 | ||||
| ViZDoom | 提供了用AI玩毁灭战士游戏的环境 | C++, Lua, Java, Python | Linux,Windows,Mac OS | 官网 论文 教程 | |
| Roboschool | 类似MuJoCo的场景,还有交互控制,及多智能体控制场景。 | Python | Linux, Mac OS | 博客 | |
| Multi-Agent Particle Environment | 多智能体粒子世界。主要用于多智能体场景下的DRL相关研究。 | Python | Linux | 论文 论文 |
四、研究框架
| 名称 | 简介 | 场景 | 语言 | 研发机构 |
|---|---|---|---|---|
| RLLib | 研究强化学习算法的框架,OpenAI Gym支持更广泛的环境 | |||
| OpenAI Baselines | OpenAI出的一些深度强化学习算法(DQN, PPO, TRPO, DDPG)的实现,基于TensorFlow和OpenAI Gym | |||
| TensorFlow Models | 强化学习算法集 | OpenAI Gym, MuJoCo | Python | Community |
| TensorFlow Agents | 用于在TensorFlow中构建并行强化学习算法 | OpenAI Gym | Python | |
| Universe/universe-starter-agent | 用于衡量和训练游戏中的AI的软件平台 | Atari, CarPole,Flashgames,Browser task, etc. | Python | OpenAI |
| ELF | 可以让多个游戏实例并行执行 | MiniRTS, Atari, Go | Python | |
| Coach | 基于Python语言的强化学习研究框架 | OpenAI Gym, ViZDoom, Roboschool, GymExtensions, PyBullet | Python | Intel |
| Unity Machine Learning Agents | 可以结合Unity Editor来创建自定义的强化学习实验场景 | 3D Balance Ball, GridWorld | Python | Unity |
五、经典框架
1、gym
OpenAI 创建的 Gym 是开源的 Python 库,通过提供一个用于在学习算法和环境之间通信的标准 API 以及一组符合该 API 的标准环境,来开发和比较强化学习(DL)算法。

